Bitbucketthe Remote Authentication Server Is Not Available Please Try Again Later
Repos for Git integration
Note
Support for capricious files in Databricks Repos is now in Public Preview. For details, run across Work with non-notebook files in a Databricks repo and Import Python and R modules.
To support best practices for information scientific discipline and engineering science code development, Databricks Repos provides repository-level integration with Git providers. You lot can develop code in a Databricks notebook and sync it with a remote Git repository. Databricks Repos lets you lot apply Git functionality such as cloning a remote repo, managing branches, pushing and pulling changes, and visually comparison differences upon commit.
Databricks Repos also provides an API that you can integrate with your CI/CD pipeline. For example, you tin can programmatically update a Databricks repo and so that it ever has the most recent code version.
Databricks Repos provides security features such every bit let lists to command admission to Git repositories and detection of clear text secrets in source code.
When audit logging is enabled, audit events are logged when you lot interact with a Databricks repo. For case, an audit effect is logged when y'all create, update, or delete a Databricks repo, when you lot list all Databricks Repos associated with a workspace, and when yous sync changes betwixt your Databricks repo and the Git remote.
For more data about best practices for code development using Databricks Repos, come across Best practices for integrating Databricks Repos with CI/CD workflows.
Requirements
Databricks supports these Git providers:
-
GitHub
-
Bitbucket
-
GitLab
-
Azure DevOps (not available in Azure China regions)
-
AWS CodeCommit
-
GitHub AE
The Git server must exist accessible from Databricks. Databricks does not back up private Git servers, such as Git servers behind a VPN.
Back up for arbitrary files in Databricks Repos is available in Databricks Runtime 8.iv and to a higher place.
Configure your Git integration with Databricks
Note
-
Databricks recommends that you lot set an expiration engagement for all personal access tokens.
-
If you are using GitHub AE and you have enabled GitHub allow lists, you lot must add Databricks control plane NAT IPs to the permit list. Use the IP for the region that the Databricks workspace is in.
-
Click
 Settings in your Databricks workspace and select User Settings from the menu.
Settings in your Databricks workspace and select User Settings from the menu. -
On the User Settings page, go to the Git Integration tab.
-
Follow the instructions for integration with GitHub, Bitbucket Deject, GitLab, Azure DevOps, AWS CodeCommit, or GitHub AE.
For Azure DevOps, Git integration does non support Azure Active Directory tokens. Y'all must use an Azure DevOps personal access token.
-
If your organization has SAML SSO enabled in GitHub, ensure that you take authorized your personal access token for SSO.
Enable back up for capricious files in Databricks Repos
In addition to syncing notebooks with a remote Git repository, Files in Repos lets you sync whatsoever type of file, such as .py files, data files in .csv or .json format, or .yaml configuration files. You can import and read these files inside a Databricks repo. You lot can also view and edit plain text files in the UI.
If back up for this feature is not enabled, you will still run across not-notebook files in your repo, but you volition non be able to work with them.
Requirements
To work with non-notebook files in Databricks Repos, you must be running Databricks Runtime viii.4 or above.
Enable Files in Repos
An admin can enable this feature as follows:
-
Get to the Admin Console.
-
Click the Workspace Settings tab.
-
In the Repos department, click the Files in Repos toggle.
Afterwards the feature has been enabled, yous must restart your cluster and refresh your browser before you can use Files in Repos.
Additionally, the kickoff time you lot access a repo after Files in Repos is enabled, you must open the Git dialog. A dialog appears indicating that you must perform a pull operation to sync non-notebook files in the repo. Select Agree and Pull to sync files. If there are whatsoever merge conflicts, another dialog appears giving you the option of discarding your conflicting changes or pushing your changes to a new branch.
Confirm Files in Repos is enabled
You can use the command %sh pwd in a notebook inside a Repo to check if Files in Repos is enabled.
-
If Files in Repos is not enabled, the response is
/databricks/commuter. -
If Files in Repos is enabled, the response is
/Workspace/Repos/<path to notebook directory>.
Clone a remote Git repository
Yous can clone a remote Git repository and work on your notebooks or files in Databricks. You tin can create notebooks, edit notebooks and other files, and sync with the remote repository. You lot can also create new branches for your development work. For some tasks you must work in your Git provider, such as creating a PR, resolving conflicts, merging or deleting branches, or rebasing a branch.
-
Click
 Repos in the sidebar.
Repos in the sidebar. -
Click Add Repo.

-
In the Add together Repo dialog, click Clone remote Git repo and enter the repository URL. Select your Git provider from the drop-downward carte du jour, optionally change the proper noun to use for the Databricks repo, and click Create. The contents of the remote repository are cloned to the Databricks repo.
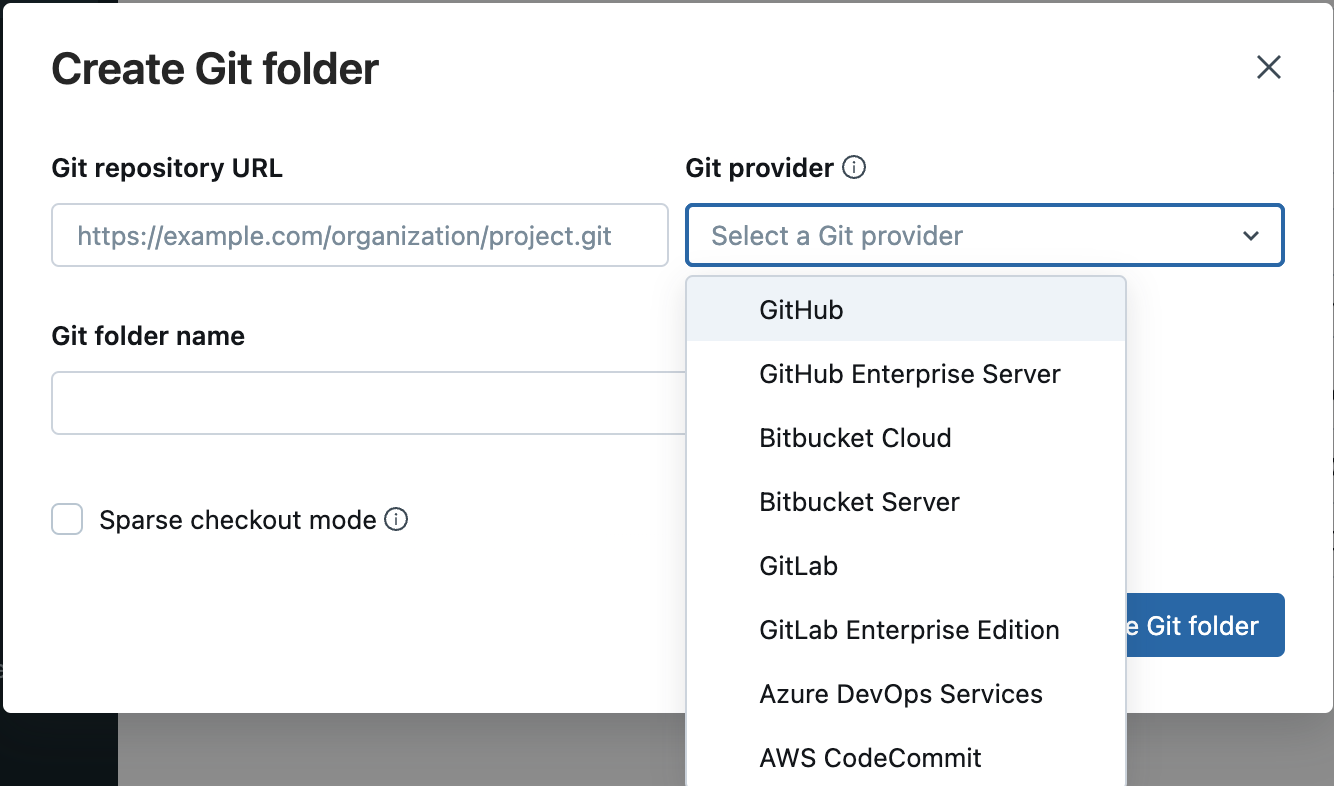
Work with notebooks in a Databricks repo
To create a new notebook or folder in a repo, click the downwards pointer next to the repo proper noun, and select Create > Notebook or Create > Folder from the menu.

To move an notebook or folder in your workspace into a repo, navigate to the notebook or binder and select Motion from the driblet-down carte du jour:
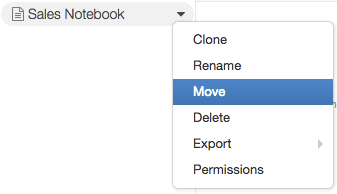
In the dialog, select the repo to which y'all want to move the object:

You can import a SQL or Python file as a single-cell Databricks notebook.
-
Add together the comment line
-- Databricks notebook sourceat the elevation of a SQL file. -
Add together the comment line
# Databricks notebook sourceat the summit of a Python file.
Work with not-notebook files in a Databricks repo
This section covers how to add files to a repo and view and edit files.
Requirements
Databricks Runtime 8.4 or above.
Create a new file
The almost common fashion to create a file in a repo is to clone a Git repository. Y'all can also create a new file directly from the Databricks repo. Click the downwards arrow next to the repo name, and select Create > File from the carte.

Import a file
To import a file, click the downwards arrow next to the repo proper name, and select Import.

The import dialog appears. You lot can drag files into the dialog or click browse to select files.

-
Simply notebooks tin be imported from a URL.
-
When you import a .zip file, Databricks automatically unzips the file and imports each file and notebook that is included in the .zip file.
Edit a file
To edit a file in a repo, click the filename in the Repos browser. The file opens and you lot tin can edit it. Changes are saved automatically.
When yous open a Markdown ( .md ) file, the rendered view is displayed by default. To edit the file, click in the file editor. To render to preview way, click anywhere outside of the file editor.
Refactor code
A best practice for code development is to modularize lawmaking so it can exist easily reused. You tin can create custom Python files in a repo and brand the code in those files available to a notebook using the import argument. For an case, run across the example notebook.
To refactor notebook code into reusable files:
-
From the Repos UI, create a new branch.
-
Create a new source lawmaking file for your lawmaking.
-
Add together Python import statements to the notebook to make the lawmaking in your new file bachelor to the notebook.
-
Commit and push button your changes to your Git provider.
Access files in a repo programmatically
You lot tin can programmatically read small-scale data files in a repo, such as .csv or .json files, straight from a notebook. You cannot programmatically create or edit files from a notebook.
import pandas as pd df = pd . read_csv ( "./data/winequality-red.csv" ) df You tin employ Spark to admission files in a repo. Spark requires absolute file paths for file data. The absolute file path for a file in a repo is file:/Workspace/Repos/<user_folder>/<repo_name>/file .
You tin copy the absolute or relative path to a file in a repo from the drop-down carte du jour next to the file:
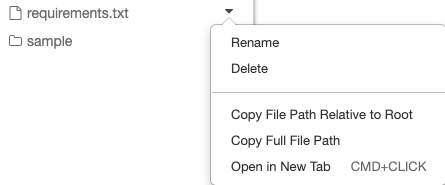
The example below shows the utilize of {bone.getcwd()} to get the full path.
import bone spark . read . format ( "csv" ) . load ( f "file: { bone . getcwd () } /my_data.csv" ) Example notebook
This notebook shows examples of working with arbitrary files in Databricks Repos.
Work with Python and R modules
Requirements
Databricks Runtime 8.four or to a higher place.
Import Python and R modules
The current working directory of your repo and notebook are automatically added to the Python path. When you work in the repo root, y'all can import modules from the root directory and all subdirectories.
To import modules from another repo, y'all must add that repo to sys.path . For instance:
import sys sys . path . append ( "/Workspace/Repos/<user-proper noun>/<repo-proper name>" ) # to use a relative path import sys import os sys . path . append ( os . path . abspath ( '..' )) You import functions from a module in a repo only as you would from a module saved as a cluster library or notebook-scoped library:
from sample import ability power . powerOfTwo ( 3 ) source ( "sample.R" ) ability.powerOfTwo ( three ) Import Databricks Python notebooks
To distinguish between a regular Python file and a Databricks Python-linguistic communication notebook exported in source-code format, Databricks adds the line # Databricks Notebook source at the elevation of the notebook source code file.
When y'all import the notebook, Databricks recognizes it and imports it as a notebook, non equally a Python module.
If you want to import the notebook as a Python module, you must edit the notebook in a lawmaking editor and remove the line # Databricks Notebook source . Removing that line converts the notebook to a regular Python file.
Import precedence rules
When y'all use an import statement in a notebook in a repo, the library in the repo takes precedence over a library or wheel with the same name that is installed on the cluster.
Autoreload for Python modules
While developing Python lawmaking, if you are editing multiple files, y'all tin use the following commands in whatever jail cell to force a reload of all modules.
% load_ext autoreload % autoreload two Use Databricks spider web last for testing
Yous can employ Databricks web last to examination modifications to your Python or R code without having to import the file to a notebook and execute the notebook.
-
Open web terminal.
-
Modify to the Repo directory:
cd /Workspace/Repos/<path_to_repo>/. -
Run the Python or R file:
python file_name.pyorRscript file_name.r.
Sync with a remote Git repository
To sync with Git, utilize the Git dialog. The Git dialog lets y'all pull changes from your remote Git repository and push and commit changes. You can as well change the branch yous are working on or create a new branch.
Important
Git operations that pull in upstream changes clear the notebook state. For more information, see Incoming changes clear the notebook state.
Open the Git dialog
You tin access the Git dialog from a notebook or from the Databricks Repos browser.
-
From a notebook, click the button at the top left of the notebook that identifies the current Git branch.

-
From the Databricks Repos browser, click the button to the correct of the repo name:
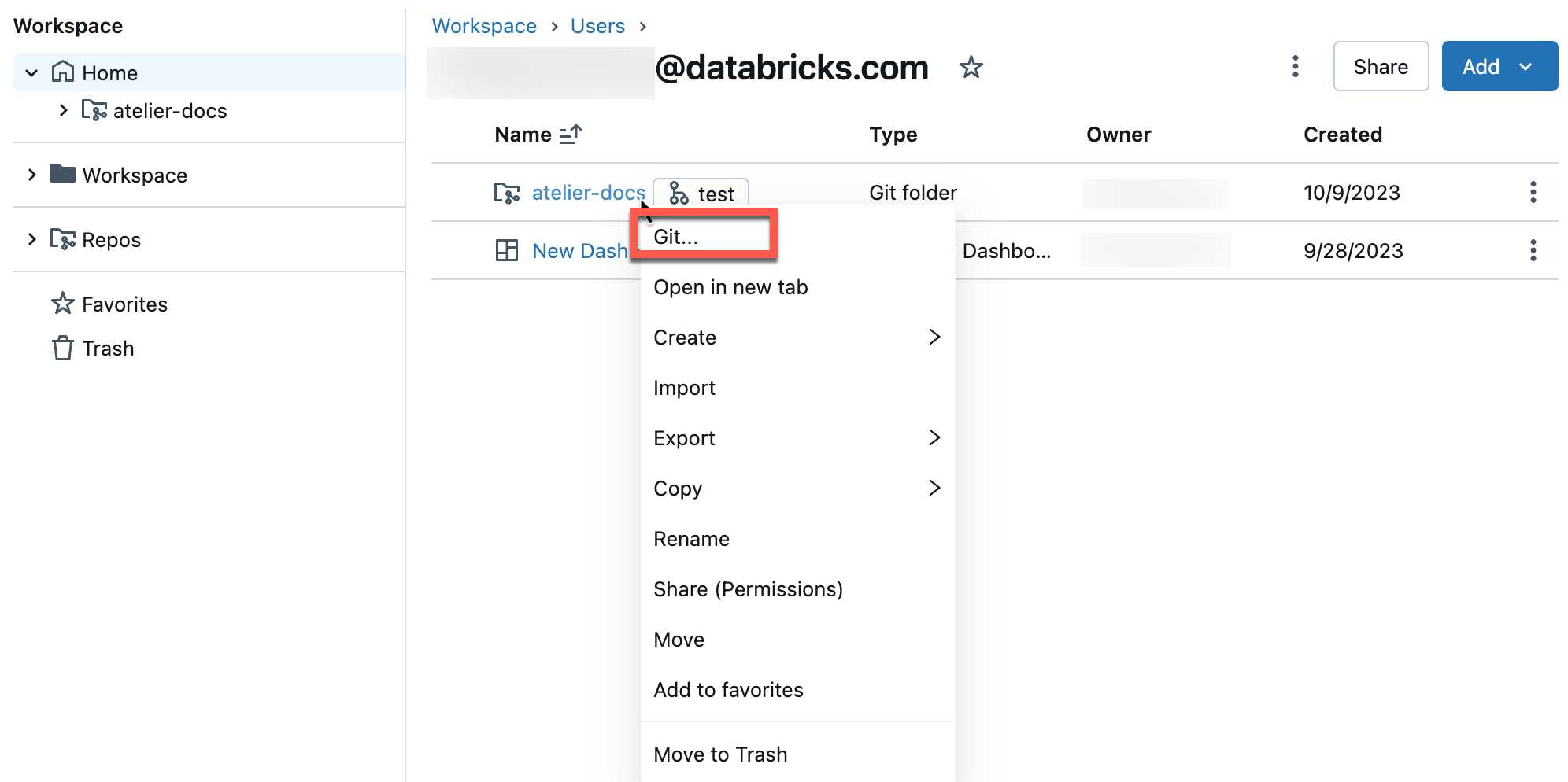
You lot can as well click the down arrow next to the repo proper name, and select Git… from the menu.

Pull changes from the remote Git repository
To pull changes from the remote Git repository, click  in the Git dialog. Notebooks and other files are updated automatically to the latest version in your remote repository.
in the Git dialog. Notebooks and other files are updated automatically to the latest version in your remote repository.
See Merge conflicts for instructions on resolving merge conflicts.
Merge conflicts
To resolve a merge disharmonize, yous must either discard conflicting changes or commit your changes to a new branch and then merge them into the original feature co-operative using a pull asking.
-
If there is a merge disharmonize, the Repos UI shows a notice allowing you to abolish the pull or resolve the disharmonize. If yous select Resolve conflict using PR, a dialog appears that lets you create a new co-operative and commit your changes to it.

-
When you click Commit to new branch, a discover appears with a link: Create a pull request to resolve merge conflicts. Click the link to open your Git provider.

-
In your Git provider, create the PR, resolve the conflicts, and merge the new co-operative into the original branch.
-
Render to the Repos UI. Use the Git dialog to pull changes from the Git repository to the original branch.
Commit and push changes to the remote Git repository
When yous take added new notebooks or files, or made changes to existing notebooks or files, the Git dialog highlights the changes.
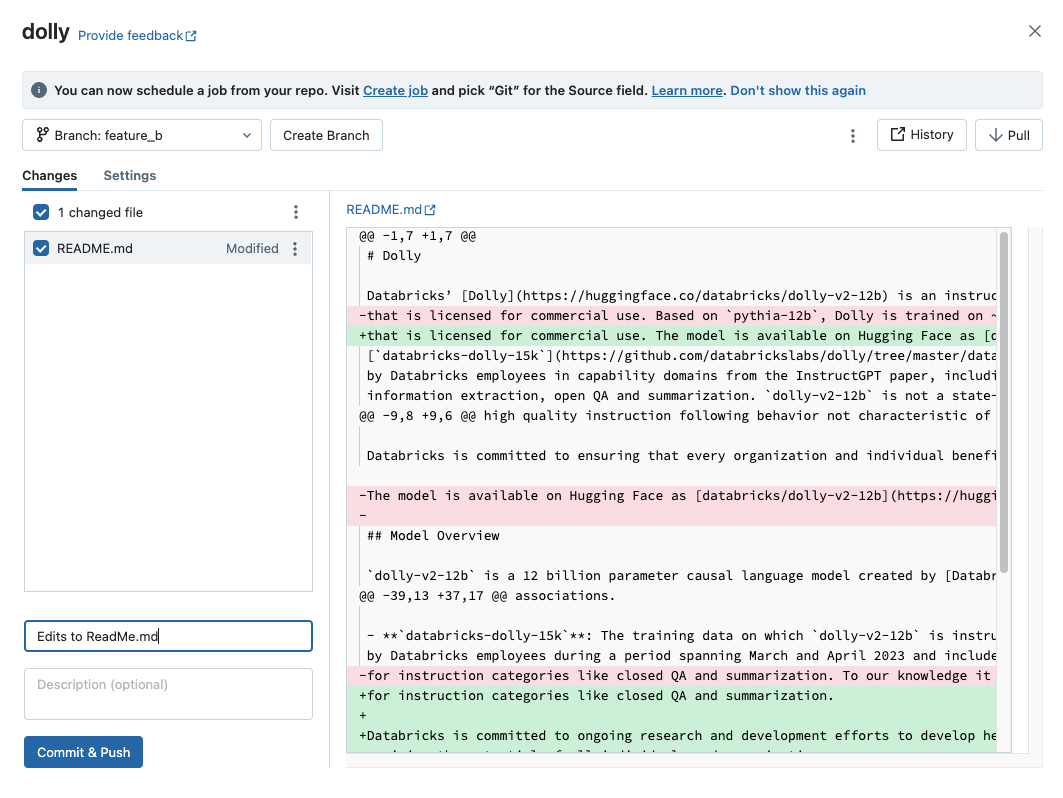
Add a required Summary of the changes, and click Commit & Push to push these changes to the remote Git repository.
If yous don't have permission to commit to the default branch, such as main , create a new branch and use your Git provider interface to create a pull request (PR) to merge it into the default branch.
Note
-
Results are not included with a notebook commit. All results are cleared before the commit is fabricated.
-
For instructions on resolving merge conflicts, run into Merge conflicts.
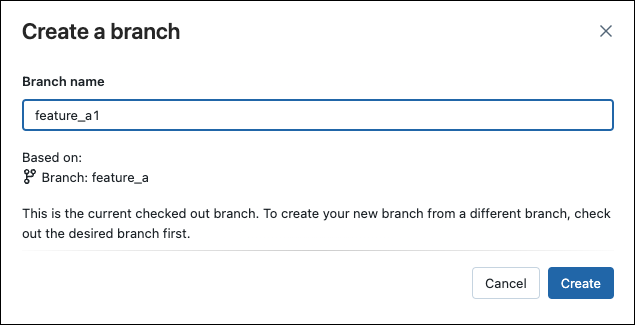
Create a new branch
You can create a new branch based on an existing branch from the Git dialog:
Control access to Databricks Repos
Manage permissions
When you create a repo, you have Tin Manage permission. This lets yous perform Git operations or modify the remote repository. Y'all tin can clone public remote repositories without Git credentials (personal access token and username). To modify a public remote repository, or to clone or modify a individual remote repository, you must accept a Git provider username and personal access token with read and write permissions for the remote repository.
Use allow lists
An admin tin limit which remote repositories users tin commit and push to.
-
Get to the Admin Panel.
-
Click the Workspace Settings tab.
-
In the Avant-garde department, click the Enable Repos Git URL Allow Listing toggle.
-
Click Confirm.
-
In the field next to Repos Git URL Permit List: Empty list, enter a comma-separated list of URL prefixes.
-
Click Save.
Users can merely commit and push to Git repositories that start with ane of the URL prefixes y'all specify. The default setting is "Empty listing", which disables access to all repositories. To permit access to all repositories, disable Enable Repos Git URL Allow List.
Note
-
Users tin can load and pull remote repositories even if they are not on the allow listing.
-
The list you salvage overwrites the existing set of saved URL prefixes.
-
It may have about 15 minutes for changes to accept consequence.
Secrets detection
Databricks Repos scans code for access primal IDs that brainstorm with the prefix AKIA and warns the user earlier committing.
Repos API
The Repos API allows you lot to programmatically manage Databricks Repos. For details, see Repos API 2.0.
Best practices for integrating Databricks Repos with CI/CD workflows
This department includes best practices for integrating Databricks Repos with your CI/CD workflow. The following figure shows an overview of the steps.

Admin workflow
Databricks Repos accept user-level folders and non-user top level folders. User-level folders are automatically created when users offset clone a remote repository. You can call back of Databricks Repos in user folders equally "local checkouts" that are individual for each user and where users make changes to their code.
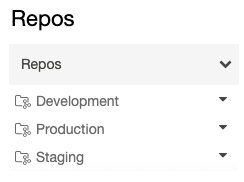
Set superlative-level folders
Admins can create non-user height level folders. The most common use case for these tiptop level folders is to create Dev, Staging, and Production folders that contain Databricks Repos for the advisable versions or branches for evolution, staging, and production. For example, if your visitor uses the Principal branch for production, the Production folder would contain Repos configured to be at the Master co-operative.
Typically permissions on these acme-level folders are read-simply for all not-admin users within the workspace.
Set upward Git automation to update Databricks Repos on merge
To ensure that Databricks Repos are ever at the latest version, you tin ready Git automation to telephone call the Repos API. In your Git provider, gear up up automation that, after every successful merge of a PR into the chief co-operative, calls the Repos API endpoint on the appropriate repo in the Production binder to bring that repo to the latest version.
For example, on GitHub this tin exist achieved with GitHub Actions.
Developer workflow
In your user binder in Databricks Repos, clone your remote repository. A all-time do is to create a new characteristic branch, or select a previously created branch, for your piece of work, instead of directly committing and pushing changes to the main branch. Y'all can make changes, commit, and push changes in that branch. When you are set up to merge your code, create a pull request and follow the review and merge processes in Git.
Here is an case workflow.
Requirements
This workflow requires that you have already configured your Git integration.
Note
Databricks recommends that each programmer piece of work on their ain characteristic branch. Sharing feature branches amid developers tin can crusade merge conflicts, which must exist resolved using your Git provider. For data about how to resolve merge conflicts, come across Merge conflicts.
Workflow
-
Clone your existing Git repository to your Databricks workspace.
-
Employ the Repos UI to create a feature branch from the main co-operative. This example uses a single feature branch characteristic-b for simplicity. You can create and use multiple feature branches to do your work.
-
Make your modifications to Databricks notebooks and files in the Repo.
-
Commit and push your changes to your Git provider.
-
Coworkers tin can now clone the Git repository into their own user folder.
-
Working on a new co-operative, a coworker makes changes to the notebooks and files in the Repo.
-
The coworker commits and pushes their changes to the Git provider.
-
-
To merge changes from other branches or rebase the feature co-operative, you must use the Git control line or an IDE on your local arrangement. Then, in the Repos UI, utilize the Git dialog to pull changes into the feature-b branch in the Databricks Repo.
-
When you are ready to merge your piece of work to the chief branch, apply your Git provider to create a PR to merge the changes from characteristic-b.
-
In the Repos UI, pull changes to the main branch.
Production chore workflow
You can indicate a job directly to a notebook in a Databricks Repo. When a job kicks off a run, it uses the current version of the lawmaking in the repo.
If the automation is setup as described in Admin workflow, every successful merge calls the Repos API to update the repo. Every bit a result, jobs that are configured to run code from a repo always use the latest version available when the job run was created.
Migration tips
If y'all are using %run commands to make Python or R functions defined in a notebook available to some other notebook, or are installing custom .whl files on a cluster, consider including those custom modules in a Databricks repo. In this way, you tin keep your notebooks and other code modules in sync, ensuring that your notebook always uses the correct version.
Migrate from %run commands
%run commands let y'all include 1 notebook within another and are oft used to make supporting Python or R code available to a notebook. In this example, a notebook named ability.py includes the code below.
# This code is in a notebook named "ability.py". def n_to_mth ( n , one thousand ): print ( n , "to the" , k , "thursday power is" , n ** m ) You can so brand functions divers in power.py available to a different notebook with a %run command:
# This notebook uses a %run control to access the code in "ability.py". % run ./ power n_to_mth ( 3 , 4 ) Using Files in Repos, you can directly import the module that contains the Python lawmaking and run the function.
from ability import n_to_mth n_to_mth ( 3 , 4 ) Migrate from installing custom Python .whl files
You tin can install custom .whl files onto a cluster and and so import them into a notebook attached to that cluster. For code that is frequently updated, this process is cumbersome and fault-prone. Files in Repos lets you keep these Python files in the aforementioned repo with the notebooks that use the lawmaking, ensuring that your notebook always uses the correct version.
For more data about packaging Python projects, encounter this tutorial.
Limitations and FAQ
In this section:
-
Incoming changes clear the notebook state
-
Prevent data loss in MLflow experiments
-
Tin can I create an MLflow experiment in a repo?
-
What happens if a job starts running on a notebook while a Git operation is in progress?
-
How can I run not-Databricks notebook files in a repo? For case, a
.pyfile? -
Can I create top-level folders that are not user folders?
-
Does Repos support GPG signing of commits?
-
How and where are the Github tokens stored in Databricks? Who would take access from Databricks?
-
Does Repos support on-premise or cocky-hosted Git servers?
-
Does Repos support Git submodules?
-
Does Repos back up SSH?
-
Does Repos support
.gitignorefiles? -
Can I pull the latest version of a repository from Git earlier running a job without relying on an external orchestration tool?
-
Can I pull in
.ipynbfiles? -
Can I consign a Repo?
-
If a library is installed on a cluster, and a library with the aforementioned proper noun is included in a folder within a repo, which library is imported?
-
Are there limits on the size of a repo or the number of files?
-
Does Repos back up branch merging?
-
Are the contents of Databricks Repos encrypted?
-
Tin can I delete a branch from a Databricks repo?
-
Where is Databricks repo content stored?
-
How can I disable Repos in my workspace?
-
Files in Repos limitations
Incoming changes clear the notebook state
Git operations that alter the notebook source lawmaking outcome in the loss of the notebook country, including jail cell results, comments, revision history, and widgets. For example, Git pull can modify the source lawmaking of a notebook. In this case, Databricks Repos must overwrite the existing notebook to import the changes. Git commit and push or creating a new branch do not affect the notebook source code, so the notebook state is preserved in these operations.
Forbid data loss in MLflow experiments
MLflow experiment information in a notebook might be lost in this scenario: You lot rename the notebook so, earlier calling whatever MLflow commands, change to a co-operative that doesn't comprise the notebook.
To prevent this situation, Databricks recommends you avoid renaming notebooks in repos.
Tin I create an MLflow experiment in a repo?
No. You can only create an MLflow experiment in the workspace.
What happens if a job starts running on a notebook while a Git performance is in progress?
At any indicate while a Git functioning is in progress, some notebooks in the Repo may accept been updated while others have not. This can crusade unpredictable beliefs.
For example, suppose notebook A calls notebook Z using a %run command. If a task running during a Git operation starts the about recent version of notebook A, but notebook Z has not however been updated, the %run command in notebook A might start the older version of notebook Z. During the Git operation, the notebook states are non anticipated and the job might fail or run notebook A and notebook Z from dissimilar commits.
Can I create top-level folders that are not user folders?
Yeah, admins tin can create pinnacle-level folders to a single depth. Repos does not support additional binder levels.
How and where are the Github tokens stored in Databricks? Who would take admission from Databricks?
-
The authentication tokens are stored in the Databricks command aeroplane, and a Databricks employee can only gain admission through a temporary credential that is audited.
-
Databricks logs the creation and deletion of these tokens, only not their usage. Databricks has logging that tracks Git operations that could be used to inspect the usage of the tokens by the Databricks application.
-
Github enterprise audits token usage. Other Git services may also have Git server auditing.
Does Repos support Git submodules?
No. You tin clone a repo that contains Git submodules, but the submodule is not cloned.
Does Repos support SSH?
No, only HTTPS.
Does Repos support .gitignore files?
Yes. If you add a file to your repo and do not want information technology to exist tracked by Git, create a .gitignore file or use one cloned from your remote repository and add the filename, including the extension.
.gitignore works only for files that are not already tracked by Git. If you add a file that is already tracked by Git to a .gitignore file, the file is still tracked by Git.
Can I pull in .ipynb files?
Yeah. The file renders in .json format, non notebook format.
Can I export a Repo?
Y'all tin can consign notebooks, folders, or an entire Repo. Yous cannot consign non-notebook files, and if you export an entire Repo, non-notebook files are not included. To export, apply the Workspace CLI or the Workspace API 2.0.
Are at that place limits on the size of a repo or the number of files?
Databricks doesn't enforce a limit on the size of a repo. However:
-
Working branches are limited to 200 MB.
-
Private files are limited to 100 MB.
Databricks recommends that in a repo:
-
The total number of all files not exceed 10,000.
-
The total number of notebooks not exceed v,000.
You lot may receive an error message if your repo exceeds these limits. You lot may also receive a timeout mistake when you clone the repo, but the performance might consummate in the background.
Does Repos support branch merging?
No. Databricks recommends that yous create a pull request and merge through your Git provider.
Are the contents of Databricks Repos encrypted?
The contents of Databricks Repos are encrypted by Databricks using a platform-managed central. Encryption using Customer-managed keys for managed services is not supported.
Can I delete a co-operative from a Databricks repo?
No. To delete a branch, you must work in your Git provider.
Where is Databricks repo content stored?
The contents of a repo are temporarily cloned onto deejay in the control plane. Databricks notebook files are stored in the control plane database just similar notebooks in the principal workspace. Non-notebook files may be stored on deejay for upward to 30 days.
How tin can I disable Repos in my workspace?
Follow these steps to disable Repos for Git in your workspace.
-
Go to the Admin Console.
-
Click the Workspace Settings tab.
-
In the Advanced section, click the Repos toggle.
-
Click Confirm.
-
Refresh your browser.
Files in Repos limitations
-
In Databricks Runtime 10.1 and beneath, Files in Repos is not compatible with Spark Streaming. To apply Spark Streaming on a cluster running Databricks Runtime 10.1 or below, you must disable Files in Repos on the cluster. Set the Spark configuration
spark.databricks.enableWsfs faux. -
Native file reads are supported in Python and R notebooks. Native file reads are not supported in Scala notebooks, only you lot can utilise Scala notebooks with DBFS as you exercise today.
-
The diff view in the Git dialog is not available for files.
-
Merely text encoded files are rendered in the UI. To view files in Databricks, the files must non exist larger than 10 MB.
-
You cannot create or edit a file from your notebook.
-
You can only export notebooks. You cannot export not-notebook files from a repo.
Troubleshooting
Error message: Invalid credentials
Try the following:
-
Confirm that the settings in the Git integration tab (User Settings > Git Integration) are correct.
-
You lot must enter both your Git provider username and token. Legacy Git integrations did not require a username, so you may need to add a username to work with Databricks Repos.
-
-
Confirm that you have selected the correct Git provider in the Add Repo dialog.
-
Ensure your personal access token or app password has the correct repo admission.
-
If SSO is enabled on your Git provider, authorize your tokens for SSO.
-
Exam your token with command line Git. Both of these options should work:
git clone https://<username>:<personal-access-token>@github.com/<org>/<repo-proper name>.git
git clone -c http.sslVerify= fake -c http.extraHeader= 'Authorization: Bearer <personal-access-token>' https://active.act.org/
Error message: Secure connection could not be established because of SSL problems
<link>: Secure connection to <link> could not be established because of SSL issues This fault occurs if your Git server is non accessible from Databricks. Private Git servers are not supported.
Timeout errors
Expensive operations such as cloning a large repo or checking out a big branch may hit timeout errors, merely the operation might complete in the background. Yous tin as well effort again after if the workspace was under heavy load at the fourth dimension.
404 errors
If yous go a 404 error when you endeavour to open a non-notebook file, try waiting a few minutes then trying again. At that place is a filibuster of a few minutes between when the workspace is enabled and when the webapp picks up the configuration flag.
resources non institute errors after pulling not-notebook files into a Databricks repo
This error tin can occur if you are not using Databricks Runtime 8.4 or to a higher place. A cluster running Databricks Runtime eight.4 or above is required to work with not-notebook files in a repo.
Errors suggesting re-cloning
There was a problem with deleting folders. The repo could be in an inconsistent country and re-cloning is recommended. This error indicates that a problem occurred while deleting folders from the repo. This could leave the repo in an inconsistent land, where folders that should have been deleted all the same be. If this error occurs, Databricks recommends deleting and re-cloning the repo to reset its land.
Unable to set repo to most recent state. This may be due to force pushes overriding commit history on the remote repo. Repo may be out of sync and re-cloning is recommended. This mistake indicates that the local and remote Git state have diverged. This can happen when a force push on the remote overrides recent commits that still exist on the local repo. Databricks does not support a hard reset within Repos and recommends deleting and re-cloning the repo if this error occurs.
My admin enabled Files in Repos, merely expected files do non appear after cloning a remote repository or pulling files into an existing one
-
Yous must refresh your browser and restart your cluster to pick upwardly the new configuration.
-
Your cluster must be running Databricks Runtime viii.4 or in a higher place.
Source: https://docs.databricks.com/repos/index.html
0 Response to "Bitbucketthe Remote Authentication Server Is Not Available Please Try Again Later"
Post a Comment